Помним ту недавнюю статью? Под капотом там из математики лемма Джонсона и Линденштрауса, она очень круто но непонятно звучит.
“Если у тебя есть много точек в пространстве очень высокой размерности, их можно спроецировать в пространство намного меньшей размерности и при этом все попарные расстояния между точками почти не изменятся.”
Чё? Меняем количество размерностей вниз и расстояние между точками сохраняется? Ну давайте проверим. Сделаем проекцию кубика на плоскость и назовём вершины A...H, а их тени на плоскости A'...H'.
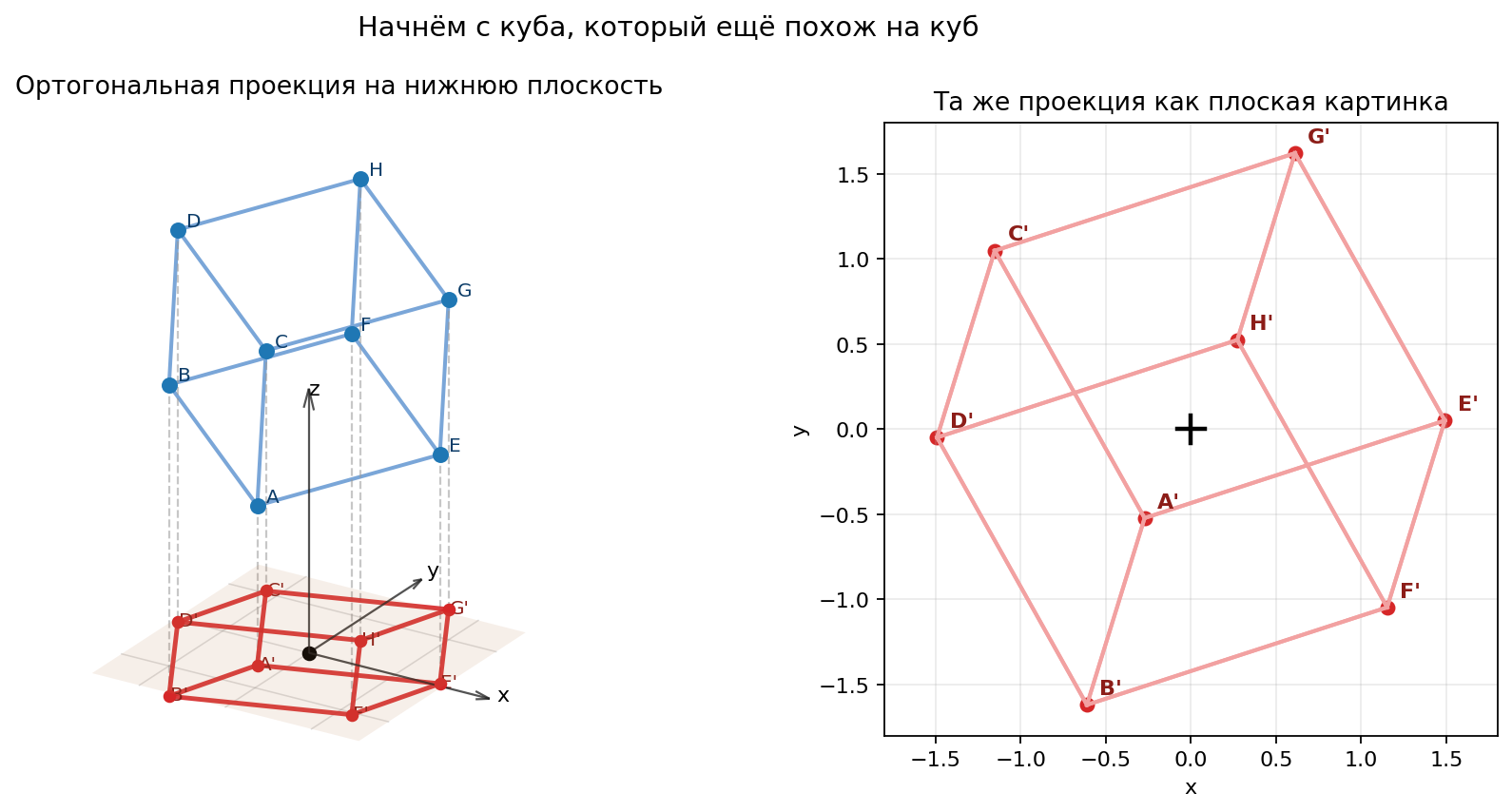
На рисуночке можно выделить CE и C'E'. Давайте явно посчитаем обе. У этих точек одинаковая координата z, так что проекция вообще ничего не теряет:
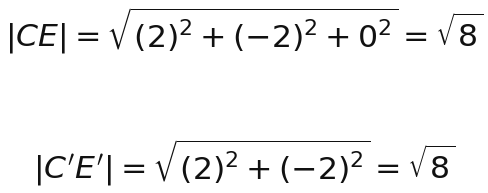
Обалдеть!!! Оно работает?? Нет, я так просто не поверю. Посчитаем все 28 попарных расстояний между вершинами куба до и после проекции.
По горизонтали и вертикали сами вершины A...H. В каждой заполненной ячейке написано до - после, а строкой ниже - насколько расстояние схлопнулось. Цвет ячейки тоже показывает величину искажения: чем зеленее, тем меньше проекция наврала; чем краснее, тем сильнее всё поехало.
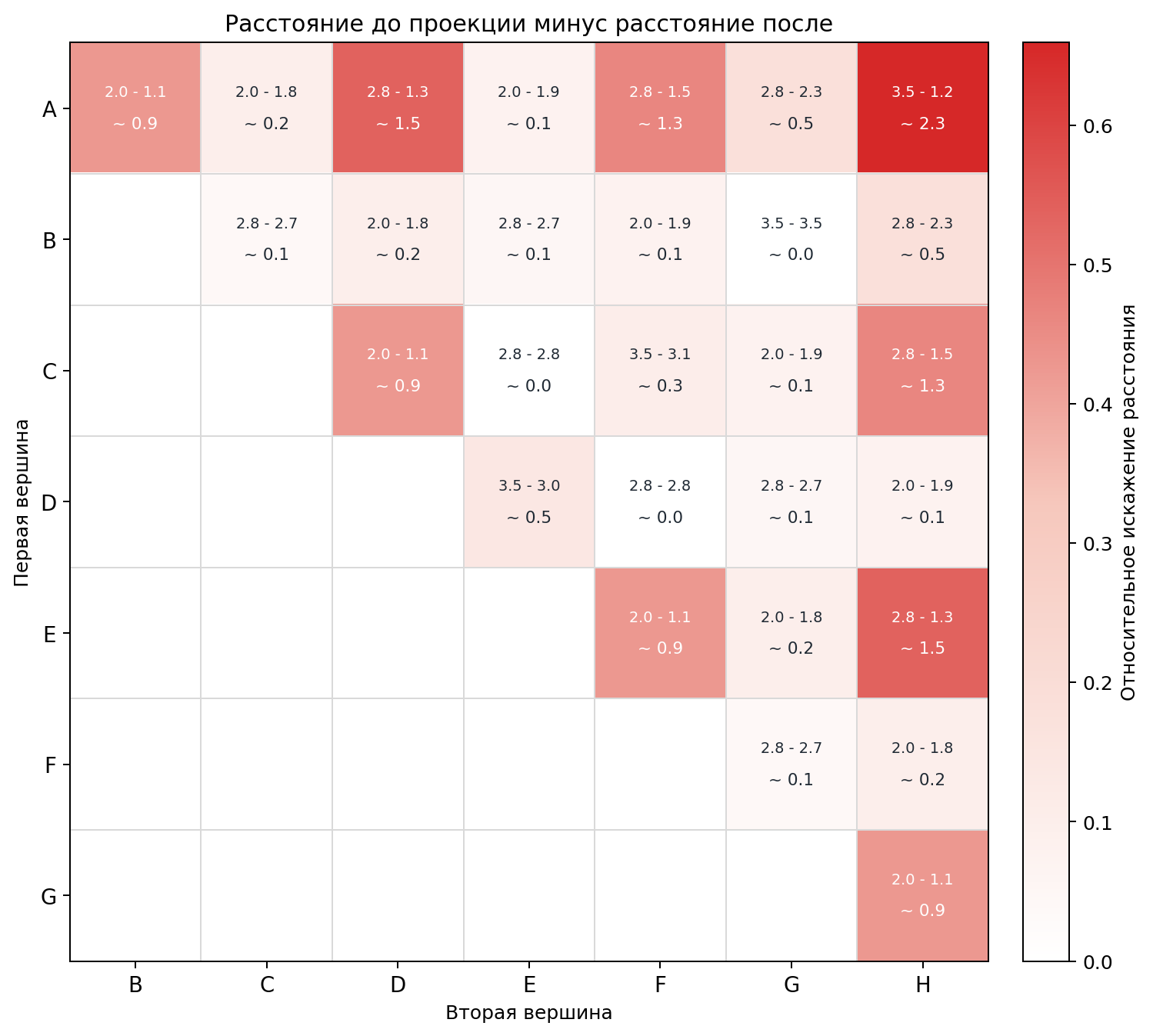
Вот тут то всё становится ясно. Обман)) AH у нас из 3.5 уменьшилось до 1.2!
Но мы на кубе не останавливаемся, друзья мои. Смысл леммы именно в словах “очень высокой размерности”. Попробуем чуть повысить размерность. Посчитаем среднее отклонение у нашего куба:
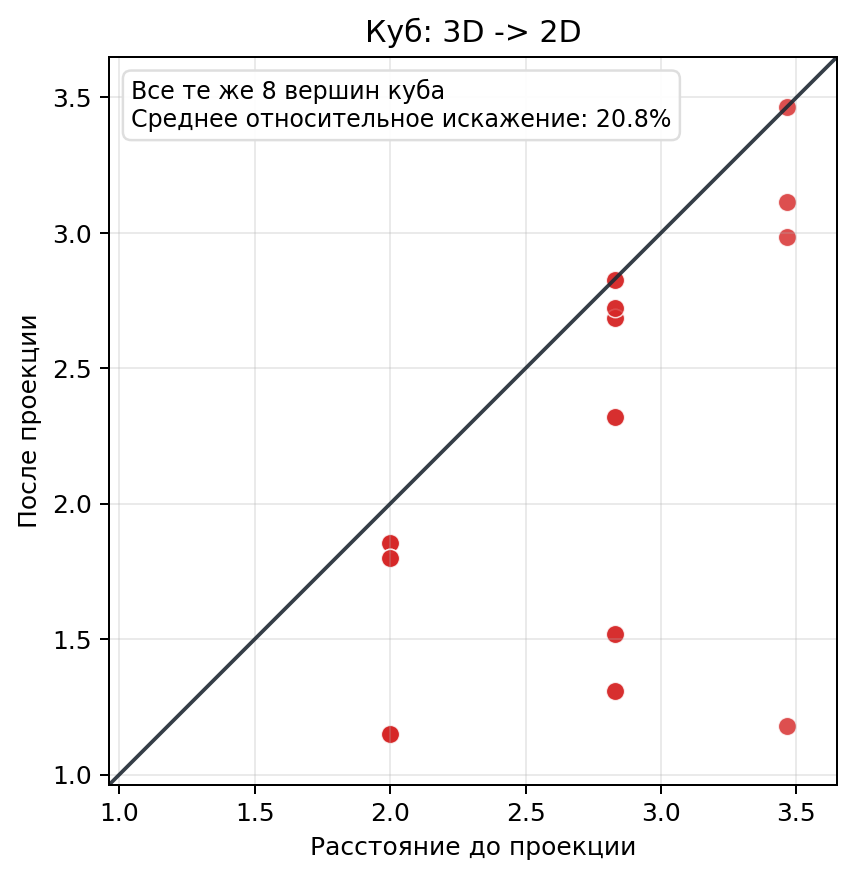
Среднее относительное искажение тут довольно жирное. Куб вообще плохой кандидат на роль “типичных данных”: он слишком регулярный, слишком игрушечный и слишком привязан к своим осям.
А теперь возьмем столько же случайных точек, примерно в таком же диапазоне попарных расстояний, но уже в 4D и 5D, и посмотрим два одиночных прогона рядом:
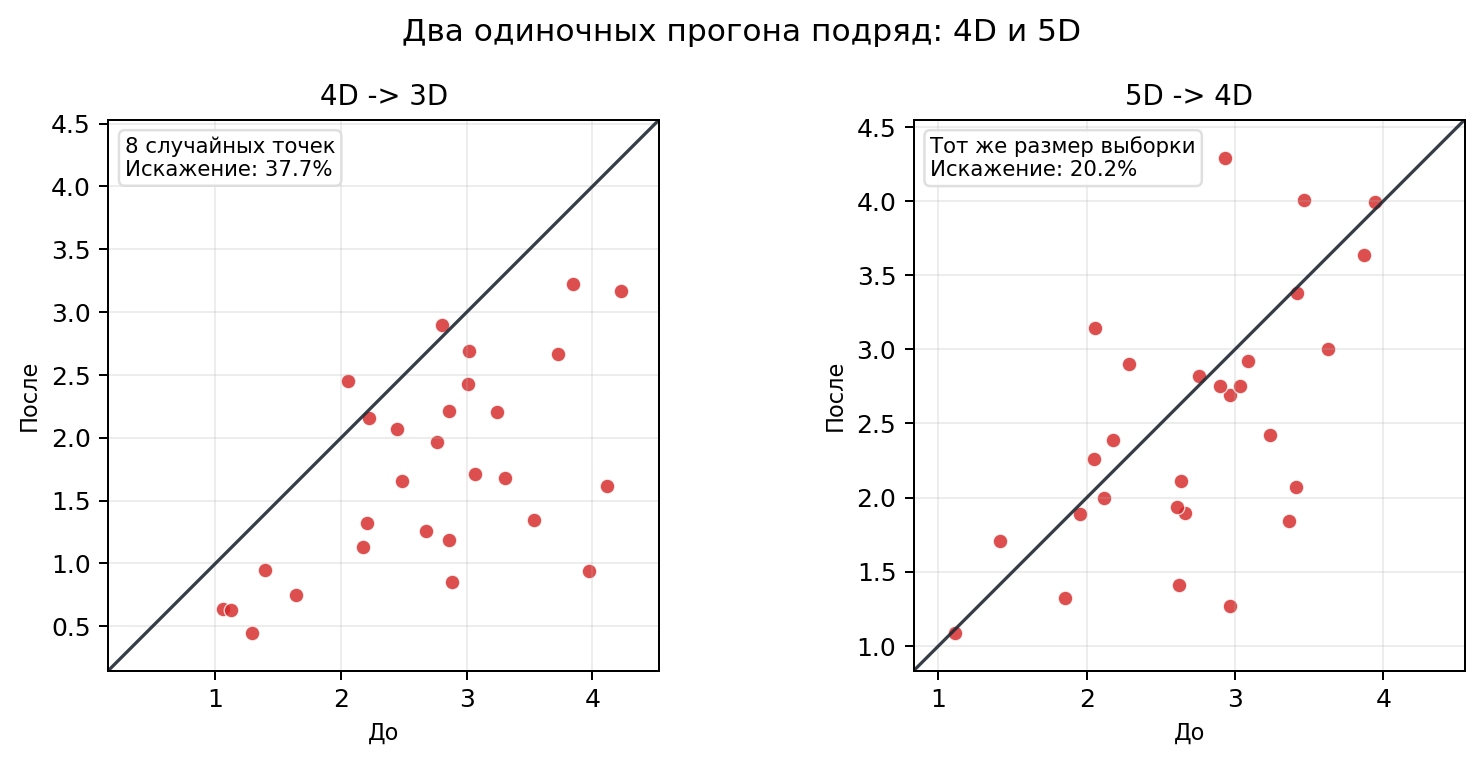
Получается, пока, не совсем понятно. В одном прогоне 4D может выглядеть даже хуже куба, а 5D уже лучше. Это нормально: точек мало, примеры шумные, глазом тут легко обмануться.
Уже лучше. И это важный кусок интуиции: когда ты теряешь одну координату из трёх, ты ампутируешь треть пространства. Когда теряешь одну координату из пяти, это уже не так драматично.
Короче, строим график:
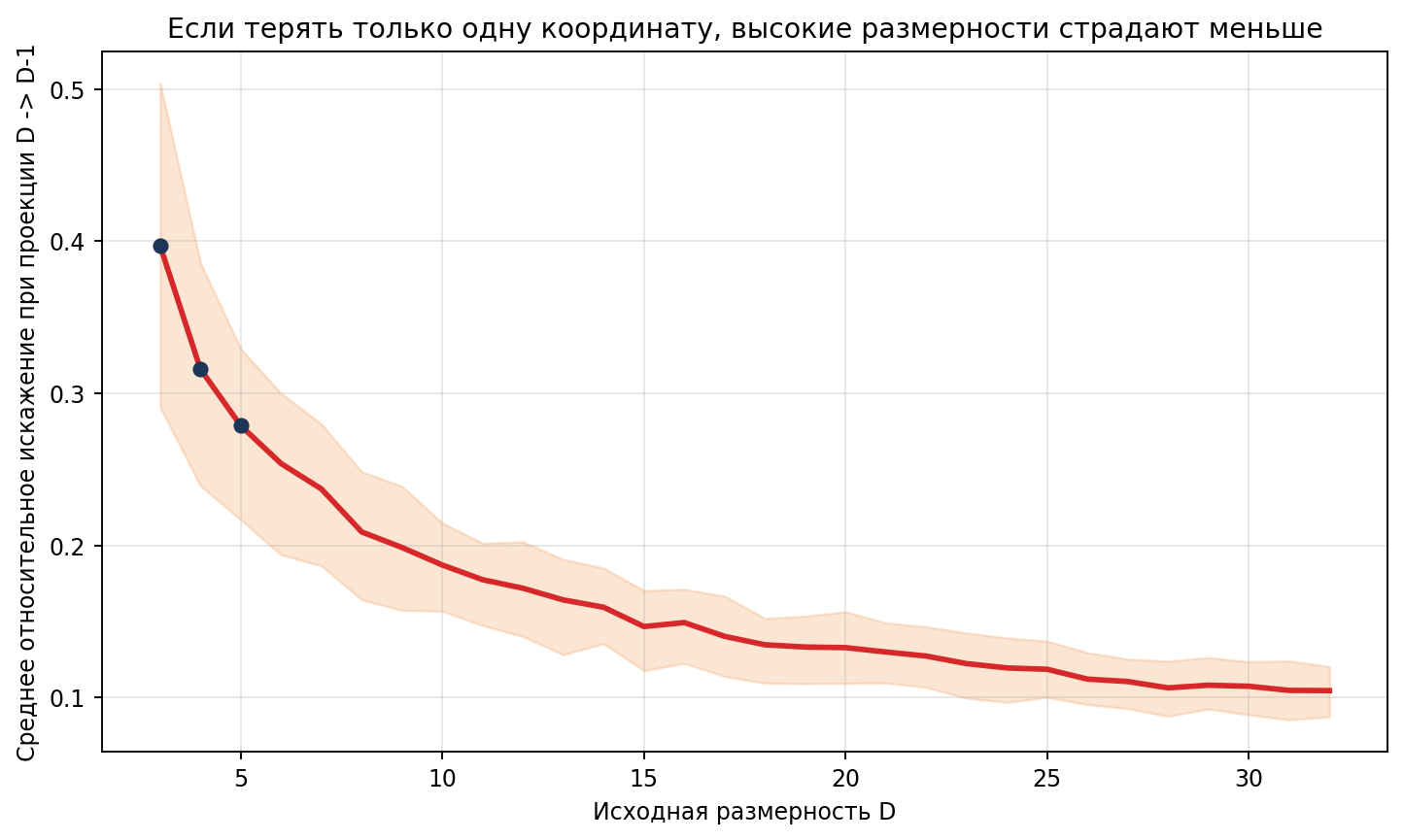
Это ещё не сама формулировка леммы Джонсона и Линденштрауса, а только разминка перед ней. Но уже видно главное: чем выше исходная размерность, тем менее катастрофичной становится потеря небольшого числа направлений.
Но среднее искажение само по себе немного жулик. Оно может выглядеть прилично, даже если несколько пар точек уже улетели в кювет.
Поэтому вводим более злой критерий. Берем допуск ε и говорим: нас устраивает только такая проекция, где для каждой пары точек новое расстояние d' попадает в коридор вокруг старого d:
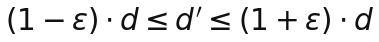
На графике “до и после” это не какая-то абстракция, а просто клин вокруг диагонали d' = d. Чем меньше ε, тем уже клин и тем вреднее проверка. Чем больше ε, тем легче объявить победу, но тем слабее смысл фразы “расстояния почти сохранились”.
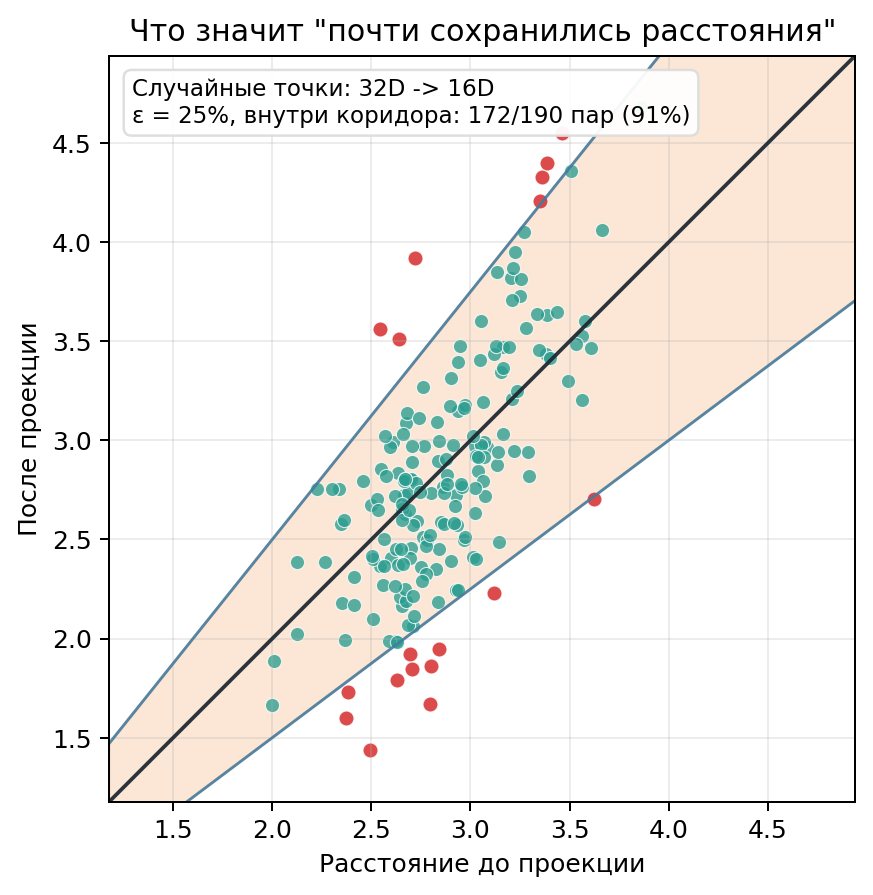
Вот теперь можно честно формализовать, что значит “почти не изменились”. В оригинальной статье Джонсона и Линденштрауса 1984 года запись суше и слегка в других терминах, но смысл уже ровно этот: все пары должны остаться внутри одного и того же ε-коридора.
Важная мысль: магия не в том, что математика заранее нашла “мусорные оси”. Наоборот, в хорошем режиме работает почти случайное сжатие. В высоких размерностях структура расстояний часто оказывается размазана так, что случайный низкоразмерный взгляд всё ещё сохраняет главное.
Именно поэтому в машинном обучении подобные штуки звучат не как философия про геометрию, а как очень практичный вопрос про память, задержку и цену работы модели.
Если записать это в привычной современной нотации, формулировка леммы примерно такая. Для любого набора из n точек и любого 0 < ε < 1 существует отображение в k измерений такое, что для любых двух точек u, v:
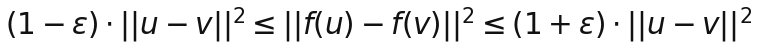
То есть все попарные расстояния сохраняются с мультипликативной ошибкой не больше ε.
А главное вот что: нужная размерность k растёт не от исходной размерности пространства, а примерно как логарифм числа точек, делённый на ε^2. В одной из стандартных оценок достаточно взять:
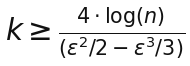
Вот где и сидит настоящий прикол. Тебе не нужно тащить исходные 10000 или 100000 координат. Если точек конечное число, а небольшое искажение терпимо, то можно ужать пространство в разы и иногда на порядки, не убив геометрию.